Reinforcement learning example with stable-baselines
![]()
NeuroGym is a toolkit that allows training any network model on many established neuroscience tasks techniques such as standard Supervised Learning or Reinforcement Learning (RL). In this notebook we will use RL to train an LSTM network on the classical Random Dots Motion (RDM) task (Britten et al. 1992).
We first show how to install the relevant toolboxes. We then show how build the task of interest (in the example the RDM task), wrapp it with the pass-reward wrapper in one line and visualize the structure of the final task. Finally we train an LSTM network on the task using the A2C algorithm Mnih et al. 2016 implemented in the stable-baselines toolbox, and plot the results.
It is straightforward to change the code to train a network on any other available task or using a different RL algorithm (e.g. ACER, PPO2).
Installation
(only for running in Google Colab)
[1]:
%tensorflow_version 1.x
# Install gym
! pip install gym
# Install neurogym
! git clone https://github.com/gyyang/neurogym.git
%cd neurogym/
! pip install -e .
# Install stable-baselines
! pip install --upgrade stable-baselines
TensorFlow 1.x selected.
Requirement already satisfied: gym in /usr/local/lib/python3.6/dist-packages (0.17.2)
Requirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from gym) (1.4.1)
Requirement already satisfied: cloudpickle<1.4.0,>=1.2.0 in /usr/local/lib/python3.6/dist-packages (from gym) (1.3.0)
Requirement already satisfied: numpy>=1.10.4 in /usr/local/lib/python3.6/dist-packages (from gym) (1.18.5)
Requirement already satisfied: pyglet<=1.5.0,>=1.4.0 in /usr/local/lib/python3.6/dist-packages (from gym) (1.5.0)
Requirement already satisfied: future in /usr/local/lib/python3.6/dist-packages (from pyglet<=1.5.0,>=1.4.0->gym) (0.16.0)
fatal: destination path 'neurogym' already exists and is not an empty directory.
/content/neurogym
Obtaining file:///content/neurogym
Requirement already satisfied: numpy in /usr/local/lib/python3.6/dist-packages (from neurogym==0.0.1) (1.18.5)
Requirement already satisfied: gym in /usr/local/lib/python3.6/dist-packages (from neurogym==0.0.1) (0.17.2)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.6/dist-packages (from neurogym==0.0.1) (3.2.2)
Requirement already satisfied: pyglet<=1.5.0,>=1.4.0 in /usr/local/lib/python3.6/dist-packages (from gym->neurogym==0.0.1) (1.5.0)
Requirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from gym->neurogym==0.0.1) (1.4.1)
Requirement already satisfied: cloudpickle<1.4.0,>=1.2.0 in /usr/local/lib/python3.6/dist-packages (from gym->neurogym==0.0.1) (1.3.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->neurogym==0.0.1) (1.2.0)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->neurogym==0.0.1) (2.4.7)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib->neurogym==0.0.1) (0.10.0)
Requirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->neurogym==0.0.1) (2.8.1)
Requirement already satisfied: future in /usr/local/lib/python3.6/dist-packages (from pyglet<=1.5.0,>=1.4.0->gym->neurogym==0.0.1) (0.16.0)
Requirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from cycler>=0.10->matplotlib->neurogym==0.0.1) (1.12.0)
Installing collected packages: neurogym
Found existing installation: neurogym 0.0.1
Can't uninstall 'neurogym'. No files were found to uninstall.
Running setup.py develop for neurogym
Successfully installed neurogym
Requirement already up-to-date: stable-baselines in /usr/local/lib/python3.6/dist-packages (2.10.0)
Requirement already satisfied, skipping upgrade: scipy in /usr/local/lib/python3.6/dist-packages (from stable-baselines) (1.4.1)
Requirement already satisfied, skipping upgrade: opencv-python in /usr/local/lib/python3.6/dist-packages (from stable-baselines) (4.1.2.30)
Requirement already satisfied, skipping upgrade: numpy in /usr/local/lib/python3.6/dist-packages (from stable-baselines) (1.18.5)
Requirement already satisfied, skipping upgrade: matplotlib in /usr/local/lib/python3.6/dist-packages (from stable-baselines) (3.2.2)
Requirement already satisfied, skipping upgrade: gym[atari,classic_control]>=0.11 in /usr/local/lib/python3.6/dist-packages (from stable-baselines) (0.17.2)
Requirement already satisfied, skipping upgrade: joblib in /usr/local/lib/python3.6/dist-packages (from stable-baselines) (0.15.1)
Requirement already satisfied, skipping upgrade: cloudpickle>=0.5.5 in /usr/local/lib/python3.6/dist-packages (from stable-baselines) (1.3.0)
Requirement already satisfied, skipping upgrade: pandas in /usr/local/lib/python3.6/dist-packages (from stable-baselines) (1.0.5)
Requirement already satisfied, skipping upgrade: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->stable-baselines) (2.4.7)
Requirement already satisfied, skipping upgrade: python-dateutil>=2.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->stable-baselines) (2.8.1)
Requirement already satisfied, skipping upgrade: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->stable-baselines) (1.2.0)
Requirement already satisfied, skipping upgrade: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib->stable-baselines) (0.10.0)
Requirement already satisfied, skipping upgrade: pyglet<=1.5.0,>=1.4.0 in /usr/local/lib/python3.6/dist-packages (from gym[atari,classic_control]>=0.11->stable-baselines) (1.5.0)
Requirement already satisfied, skipping upgrade: Pillow; extra == "atari" in /usr/local/lib/python3.6/dist-packages (from gym[atari,classic_control]>=0.11->stable-baselines) (7.0.0)
Requirement already satisfied, skipping upgrade: atari-py~=0.2.0; extra == "atari" in /usr/local/lib/python3.6/dist-packages (from gym[atari,classic_control]>=0.11->stable-baselines) (0.2.6)
Requirement already satisfied, skipping upgrade: pytz>=2017.2 in /usr/local/lib/python3.6/dist-packages (from pandas->stable-baselines) (2018.9)
Requirement already satisfied, skipping upgrade: six>=1.5 in /usr/local/lib/python3.6/dist-packages (from python-dateutil>=2.1->matplotlib->stable-baselines) (1.12.0)
Requirement already satisfied, skipping upgrade: future in /usr/local/lib/python3.6/dist-packages (from pyglet<=1.5.0,>=1.4.0->gym[atari,classic_control]>=0.11->stable-baselines) (0.16.0)
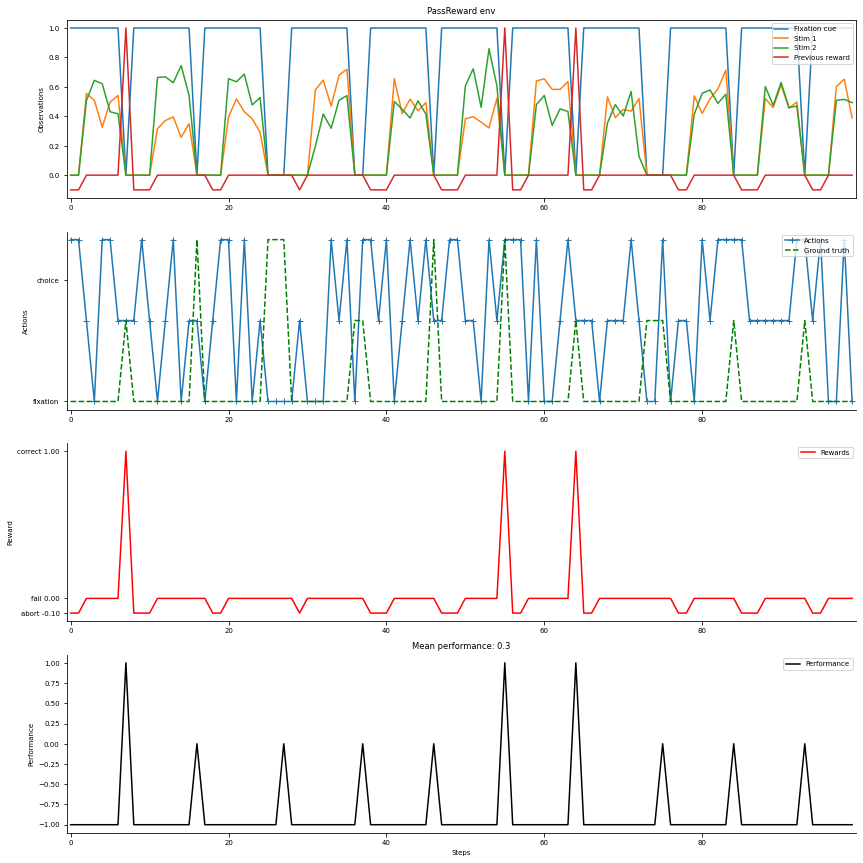
Task
here we build the Random Dots Motion task, specifying the duration of each trial period (fixation, stimulus, decision) and wrapp it with the pass-reward wrapper which appends the previous reward to the observation. We then plot the structure of the task in a figure that shows: 1. The observations received by the agent (top panel). 2. The actions taken by a random agent and the correct action at each timestep (second panel). 3. The rewards provided by the environment at each timestep (third panel). 4. The performance of the agent at each trial (bottom panel).
[2]:
import gym
import neurogym as ngym
from neurogym.wrappers import pass_reward
import warnings
warnings.filterwarnings('ignore')
# Task name
name = 'PerceptualDecisionMaking-v0'
# task specification (here we only specify the duration of the different trial periods)
timing = {'fixation': ('constant', 300),
'stimulus': ('constant', 500),
'decision': ('constant', 300)}
kwargs = {'dt': 100, 'timing': timing}
# build task
env = gym.make(name, **kwargs)
# print task properties
print(env)
# wrapp task with pass-reward wrapper
env = pass_reward.PassReward(env)
# plot example trials with random agent
data = ngym.utils.plot_env(env, fig_kwargs={'figsize': (12, 12)}, num_steps=100, ob_traces=['Fixation cue', 'Stim 1', 'Stim 2', 'Previous reward'])
findfont: Font family ['arial'] not found. Falling back to DejaVu Sans.
findfont: Font family ['arial'] not found. Falling back to DejaVu Sans.
### PerceptualDecisionMaking
Doc: Two-alternative forced choice task in which the subject has to
integrate two stimuli to decide which one is higher on average.
Args:
stim_scale: Controls the difficulty of the experiment. (def: 1., float)
sigma: float, input noise level
dim_ring: int, dimension of ring input and output
Reference paper
[The analysis of visual motion: a comparison of neuronal and psychophysical performance](https://www.jneurosci.org/content/12/12/4745)
Period timing (ms)
fixation : constant 300
stimulus : constant 500
delay : constant 0
decision : constant 300
Reward structure
abort : -0.1
correct : 1.0
fail : 0.0
Tags: perceptual, two-alternative, supervised.
Train a network
[3]:
import warnings
from stable_baselines.common.policies import LstmPolicy
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines import A2C # ACER, PPO2
warnings.filterwarnings('default')
# Optional: PPO2 requires a vectorized environment to run
# the env is now wrapped automatically when passing it to the constructor
env = DummyVecEnv([lambda: env])
model = A2C(LstmPolicy, env, verbose=1, policy_kwargs={'feature_extraction':"mlp"})
model.learn(total_timesteps=100000, log_interval=1000)
env.close()
WARNING:tensorflow:
The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
* https://github.com/tensorflow/io (for I/O related ops)
If you depend on functionality not listed there, please file an issue.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/common/tf_util.py:191: The name tf.ConfigProto is deprecated. Please use tf.compat.v1.ConfigProto instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/common/tf_util.py:200: The name tf.Session is deprecated. Please use tf.compat.v1.Session instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/common/policies.py:116: The name tf.variable_scope is deprecated. Please use tf.compat.v1.variable_scope instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/common/input.py:25: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/common/policies.py:420: flatten (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.flatten instead.
WARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/python/layers/core.py:332: Layer.apply (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.
Instructions for updating:
Please use `layer.__call__` method instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/common/tf_layers.py:123: The name tf.get_variable is deprecated. Please use tf.compat.v1.get_variable instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/common/distributions.py:326: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/common/distributions.py:327: The name tf.log is deprecated. Please use tf.math.log instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/a2c/a2c.py:158: The name tf.summary.scalar is deprecated. Please use tf.compat.v1.summary.scalar instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/common/tf_util.py:449: The name tf.get_collection is deprecated. Please use tf.compat.v1.get_collection instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/common/tf_util.py:449: The name tf.GraphKeys is deprecated. Please use tf.compat.v1.GraphKeys instead.
WARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/python/ops/clip_ops.py:301: where (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/a2c/a2c.py:182: The name tf.train.RMSPropOptimizer is deprecated. Please use tf.compat.v1.train.RMSPropOptimizer instead.
WARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/python/training/rmsprop.py:119: calling Ones.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/a2c/a2c.py:192: The name tf.global_variables_initializer is deprecated. Please use tf.compat.v1.global_variables_initializer instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/stable_baselines/a2c/a2c.py:194: The name tf.summary.merge_all is deprecated. Please use tf.compat.v1.summary.merge_all instead.
---------------------------------
| explained_variance | -0.477 |
| fps | 10 |
| nupdates | 1 |
| policy_entropy | 1.1 |
| total_timesteps | 5 |
| value_loss | 0.00289 |
---------------------------------
---------------------------------
| explained_variance | -0.907 |
| fps | 351 |
| nupdates | 1000 |
| policy_entropy | 1.1 |
| total_timesteps | 5000 |
| value_loss | 0.0147 |
---------------------------------
---------------------------------
| explained_variance | 0.517 |
| fps | 356 |
| nupdates | 2000 |
| policy_entropy | 1.07 |
| total_timesteps | 10000 |
| value_loss | 0.554 |
---------------------------------
---------------------------------
| explained_variance | 0.182 |
| fps | 359 |
| nupdates | 3000 |
| policy_entropy | 1.05 |
| total_timesteps | 15000 |
| value_loss | 0.0563 |
---------------------------------
---------------------------------
| explained_variance | 0.558 |
| fps | 358 |
| nupdates | 4000 |
| policy_entropy | 0.808 |
| total_timesteps | 20000 |
| value_loss | 0.166 |
---------------------------------
---------------------------------
| explained_variance | 0.99 |
| fps | 358 |
| nupdates | 5000 |
| policy_entropy | 0.189 |
| total_timesteps | 25000 |
| value_loss | 0.00343 |
---------------------------------
---------------------------------
| explained_variance | 0.991 |
| fps | 360 |
| nupdates | 6000 |
| policy_entropy | 0.117 |
| total_timesteps | 30000 |
| value_loss | 0.00305 |
---------------------------------
---------------------------------
| explained_variance | 0.914 |
| fps | 362 |
| nupdates | 7000 |
| policy_entropy | 0.212 |
| total_timesteps | 35000 |
| value_loss | 0.013 |
---------------------------------
---------------------------------
| explained_variance | 0.957 |
| fps | 362 |
| nupdates | 8000 |
| policy_entropy | 0.0404 |
| total_timesteps | 40000 |
| value_loss | 0.026 |
---------------------------------
---------------------------------
| explained_variance | 0.934 |
| fps | 360 |
| nupdates | 9000 |
| policy_entropy | 0.27 |
| total_timesteps | 45000 |
| value_loss | 0.011 |
---------------------------------
---------------------------------
| explained_variance | 0.976 |
| fps | 360 |
| nupdates | 10000 |
| policy_entropy | 0.509 |
| total_timesteps | 50000 |
| value_loss | 0.00139 |
---------------------------------
---------------------------------
| explained_variance | 0.991 |
| fps | 360 |
| nupdates | 11000 |
| policy_entropy | 0.0325 |
| total_timesteps | 55000 |
| value_loss | 0.00196 |
---------------------------------
---------------------------------
| explained_variance | 0.996 |
| fps | 361 |
| nupdates | 12000 |
| policy_entropy | 0.211 |
| total_timesteps | 60000 |
| value_loss | 0.000678 |
---------------------------------
---------------------------------
| explained_variance | 0.684 |
| fps | 361 |
| nupdates | 13000 |
| policy_entropy | 0.2 |
| total_timesteps | 65000 |
| value_loss | 0.00527 |
---------------------------------
---------------------------------
| explained_variance | 0.968 |
| fps | 361 |
| nupdates | 14000 |
| policy_entropy | 0.424 |
| total_timesteps | 70000 |
| value_loss | 0.00391 |
---------------------------------
---------------------------------
| explained_variance | 0.851 |
| fps | 362 |
| nupdates | 15000 |
| policy_entropy | 0.384 |
| total_timesteps | 75000 |
| value_loss | 0.0313 |
---------------------------------
---------------------------------
| explained_variance | 0.977 |
| fps | 361 |
| nupdates | 16000 |
| policy_entropy | 0.0187 |
| total_timesteps | 80000 |
| value_loss | 0.00316 |
---------------------------------
---------------------------------
| explained_variance | 0.994 |
| fps | 362 |
| nupdates | 17000 |
| policy_entropy | 0.0252 |
| total_timesteps | 85000 |
| value_loss | 0.000824 |
---------------------------------
---------------------------------
| explained_variance | 0.957 |
| fps | 362 |
| nupdates | 18000 |
| policy_entropy | 0.206 |
| total_timesteps | 90000 |
| value_loss | 0.00319 |
---------------------------------
---------------------------------
| explained_variance | 0.992 |
| fps | 363 |
| nupdates | 19000 |
| policy_entropy | 0.0935 |
| total_timesteps | 95000 |
| value_loss | 0.00294 |
---------------------------------
---------------------------------
| explained_variance | 0.978 |
| fps | 363 |
| nupdates | 20000 |
| policy_entropy | 0.0645 |
| total_timesteps | 100000 |
| value_loss | 0.000502 |
---------------------------------
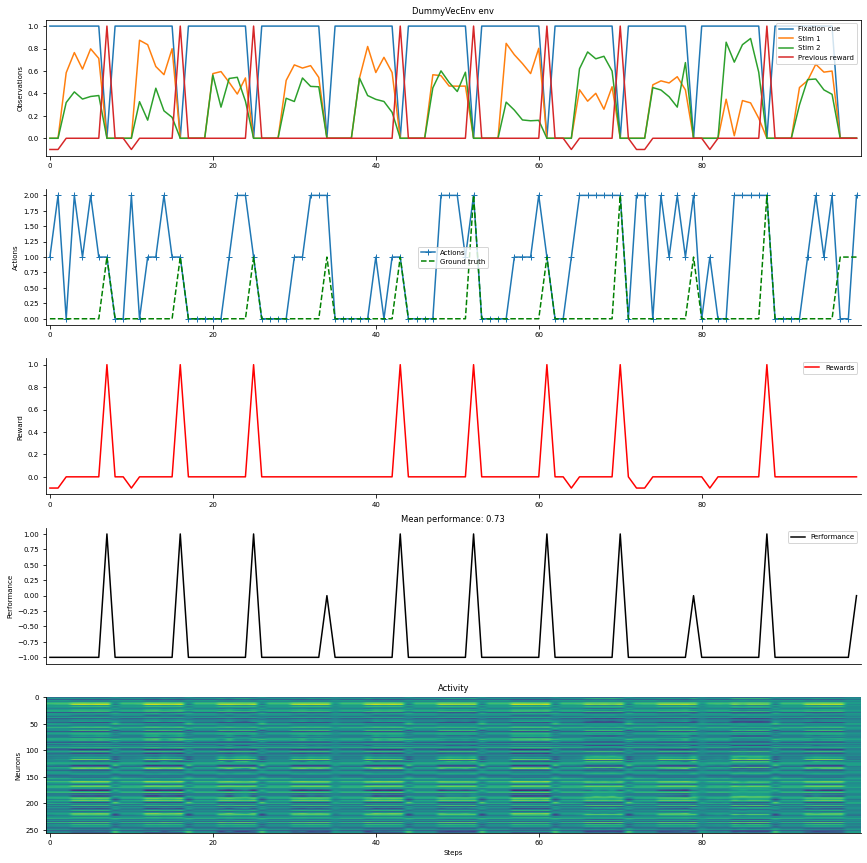
Visualize results
[6]:
env = gym.make(name, **kwargs)
# print task properties
print(env)
# wrapp task with pass-reward wrapper
env = pass_reward.PassReward(env)
env = DummyVecEnv([lambda: env])
# plot example trials with random agent
data = ngym.utils.plot_env(env, fig_kwargs={'figsize': (12, 12)}, num_steps=100, ob_traces=['Fixation cue', 'Stim 1', 'Stim 2', 'Previous reward'], model=model)
### PerceptualDecisionMaking
Doc: Two-alternative forced choice task in which the subject has to
integrate two stimuli to decide which one is higher on average.
Args:
stim_scale: Controls the difficulty of the experiment. (def: 1., float)
sigma: float, input noise level
dim_ring: int, dimension of ring input and output
Reference paper
[The analysis of visual motion: a comparison of neuronal and psychophysical performance](https://www.jneurosci.org/content/12/12/4745)
Period timing (ms)
fixation : constant 300
stimulus : constant 500
delay : constant 0
decision : constant 300
Reward structure
abort : -0.1
correct : 1.0
fail : 0.0
Tags: perceptual, two-alternative, supervised.